Frémaux & Gerstner (2016) - Neuromodulated STDP, and Theory of Three-Factor Learning Rules
27 Jun 2021The paper can found here here.
Why am I reading this review paper?
While researching supervised learning rules for SNN, one cannot escape the 3-factor learning rule 😀. This quite recent review paper nicely summarizes the influence of neuromodulation on STDP and provides experimental evidence on neuromodulation in the context of synaptic plasticity. It presents a general framework for 3-factor learning rules.
Motivation
-
Behavioral learning and memory formation are closely linked to synaptic plasticity. It is thanks to those connection strength changes between the neurons that we are able to learn new tasks or recognize novel items in our environment.
-
Classical Hebbian learning (focusing on the joint activity between pre- and postsynaptic neurons) is limited to only sub-category of problems, i.e. unsupervised learning tasks. Although STDP (as a typical example of Hebbian learning) is indeed one of the main driving forces of synaptic plasticity, it fails, by design, to consider scenarios where “reward” or “novelty” come into play.
-
Experimental results suggest that information about “reward” (success) or stimulus “novely” is conveyed by neuromodulators (ex. dopamine, acetylcholine, noradrenaline, serotonine,…) which act as “gates” to Hebbian plasticity.
Framework for 3-factor learning rule
-
In a classifical Hebbian learning can be described by $\dot w = H(pre,post)$; where $\dot w$ is the synaptic weight change and $H$ is an arbitrary function of pre- and postsynaptic neuron.
-
A Neo-Hebbian learning then takes the form of $\dot w = F(M, pre,post)$
-
In this equation, $M$ is the modulator signal, sometimes also called global signal. The pre and post are local variables as they convey information about a specific neurons (pre and post). $F$ is a function which would determine the exact type of learning.
-
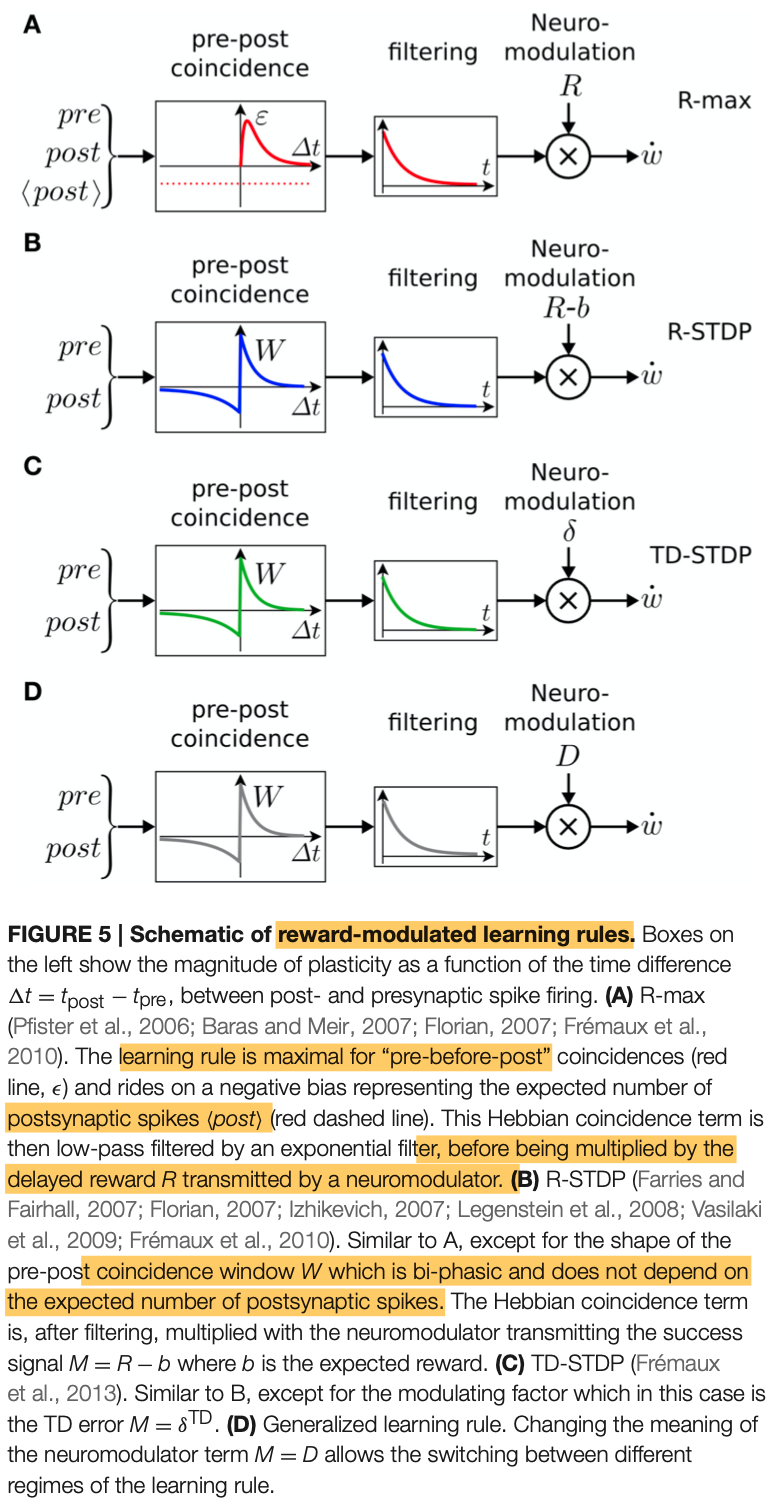
Note that the choice of $M$ term can lead to different variants of the 3-factor learning depending on the task (the neuromodulator term $M$ can hence take a different form/role). In the context of reward-driven learning models or reward-modulated learning:
-
For policy gradient models, there is the R-max rule which is derived from reward maximization.
- Synapses form an eligibility trace, a form of transient memory of pre-post (Hebbian) coincidence (which is stored at the location of the synapse, i.e local). This memory decays exponentially over time with time constant $\tau_e$. The choice of the time constant can then be used to bridge the temporal gap between the neural activity and reward signal (a reward signal might come much later after the agent has already taken a decision) - An effective change of synaptic weight only happens when a neuromodulatory signal M is available. In other words, the synapses are first “marked/flagged” then updated when M comes in.
-
R-STDP: modulates the standard STDP by a reward term
-
Temporal-difference STDP (TD-STDP): arising from a reinforcement learning paradigm. On a very high-level (mainly because that’s not my field of expertise 😅), TD learning is concerned with predicting the value of each state environment so to choose an optimal policy that would lead to the state with the highest value.
-