
Wu, et al. (2022) - Brain-inspired Global-Local Learning Incorporated with Neuromorphic Computing
10 Apr 20222. Background
3. Methods: How to formulate a hybrid learning combining LP and GP
4. HP Evaluation
5. My Critic
I presented this paper at INI Journal Club on Wednesday 28.09.2022 and thought of summarizing the paper in a blog post.
Main Contribution
This paper was recently published in Nature Communications (January 2022). It describes a hybrid learning rule combining local Hebbian-based plasticity with global error-based rules in a single meta-learning framework for SNN on neuromorphic hardware.
Background
To put things into perspective, the same group has released a fully digital neuromorphic chip named the Tianjic back in 2019. The chip is intended to be general-purpose hardware capable of implementing a broad range of algorithms from purely computer-science based algorithms to the more biologically-inspired computing algorithms.
In this paper, the group focuses on the algorithmic side and attempts to demonstrate the benefits, as I will discuss later, of the hybrid learning rule they came up with on the Tianjic chip (note this is not a full hardware implementation of the learning rule; they used a hardware simulator for that)
Local vs Global Plasticity
A big part of the neuromorphic models developed focus on one of two learning paradigms:
- (back) propagating a global error signal using gradient descent which I will refer to as global plasticity [GP]. This involves two pathways: a forward pass to compute the cost function followed by a backward pass to propagate the errors and update the weights layer by layer.
- Simple correlation based rules (Hebbian-like) which I will refer to as local plasticity [LP]. These rules are much easier to implement on the hardware and have shown promise on smaller subset of problems.
The idea of the paper is to combine both LP and GP in a hybrid plasticity framework [HP]. This framework can be summarized as learning the hyperparameters of the local plasticity rule (learning plasticity or meta-learning)
Biological relevance of meta-learning
We know from biological studies that:
Neuromodulators are media for signaling specific global variables and parameters that regulate distributed learning modules in the brain.(Doya, K. Metalearning and neuromodulation, (2002))
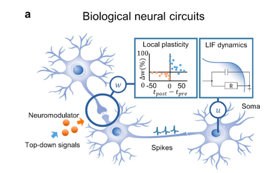
In other words, the synaptic weights are modified based on the activity of the pre and post neuron but are additionally modulated by a top-down signal. This signal can affect multiple parameters of the learning such as the learning rate, the update polarity,… etc. The idea of metalearning (aka learning to learn) in this context is hence about learning those hyperparameters of the modulatory signals.
Methods: How to formulate a hybrid learning combining LP and GP
Starting from a neuron
The authors started from the differential equation describing the membrane potential dynamics:
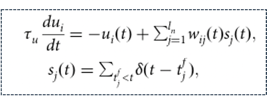
Unlike the common formulation for LIF neuron (also the one I am most used to), you can see that there are no synaptic dynamics in this first equation. Here the second term describes the effect of incoming spikes on the membrane potential $u_i$. $w_{i,j}$ is the synaptic weight between a pre neuron $j$ and post neuron $i$and $s_j$ are the train of spikes from the pre neuron.
Adding synapses…
Now to incorporate the synaptic dynamics, they expanded the weight term into two additional terms:
- The first is an exponential decay assuming an exponential synapse with time constant $\tau_w$. Another way to look at it is that at the time of arrival of a pre-spike, the synapse has a maximal weight (i.e effect on the post neuron) but then synaptic conductance decays with time.
- The second term is a generic function for Hebbian-like learning rules modeled by $P(pre,post, \theta)$. In hebbian-learning, the synaptic weights are modified based on the activity of a pre, post and some other $\theta$ hyperparameters.
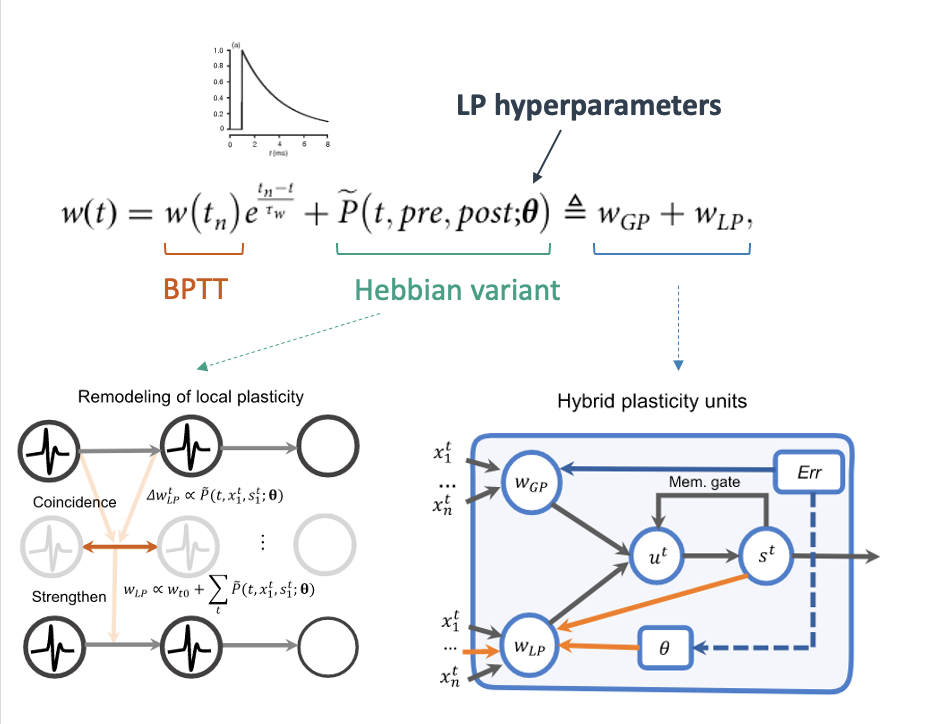
To dissect this further, what the weight equation is saying is basically that the weights can be split into two terms. One term $w(t_n)$ which is updated globally with back-propagation through time (BPTT). They also refer to it as a phasic term since it is only updated once some time T of the stimulus presentation has passed. A second term is updated more frequently at each pre-post spike (hence locally).
Now the question is: why split the weight update, right? 🤓 Simply to have those updates on different parts of the chip (at least that’s the reason to my understanding.)
Putting it all together
With this formulation they show how this can be implemented with the hybrid plasticity unit. A hybrid unit shows how LP and GP interact:
- LP updates the local part of the weight $w_{LP}$
- BPTT with surrogate gradient updates both the global part of the weight $w_{GP}$ and the hyperparameters $\theta$.
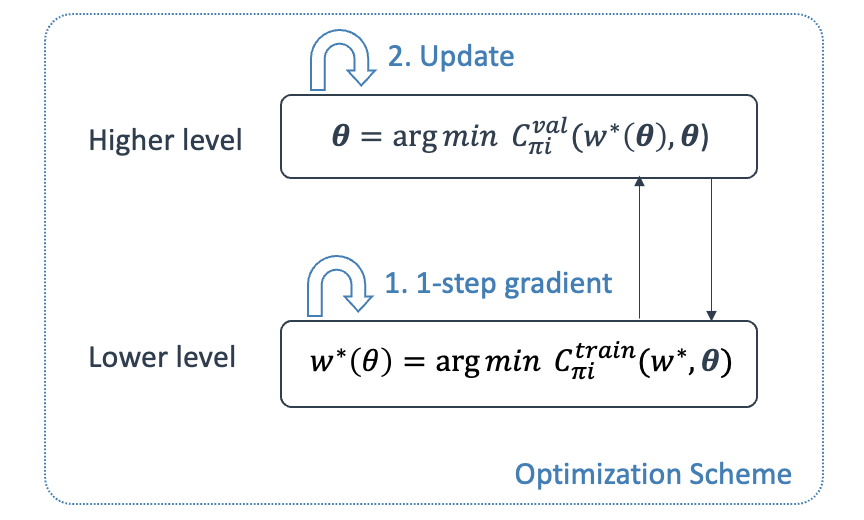
The next question to answer is how to optimize both $w_{GP}$ and $\theta$ with BPTT? The answer to this is to follow a bi-level optimization scheme:
- Since $\theta$ are meta-parameters with higher-order effect on learning, they are optimized in an outer loop with respect to a cost function defined on a validation dataset.
- The inner loop consists of 1 gradient-step to optimize $w_{GP}$ given some initial, fixed $\theta$ with respect to a cost function on a training dataset.
Minor note: I have received a question after my presentation on to why we use two different data sets for the two-optimization levels? To be honest, I know it is common practice for meta-learning but I don’t really know why.
HP Evaluation
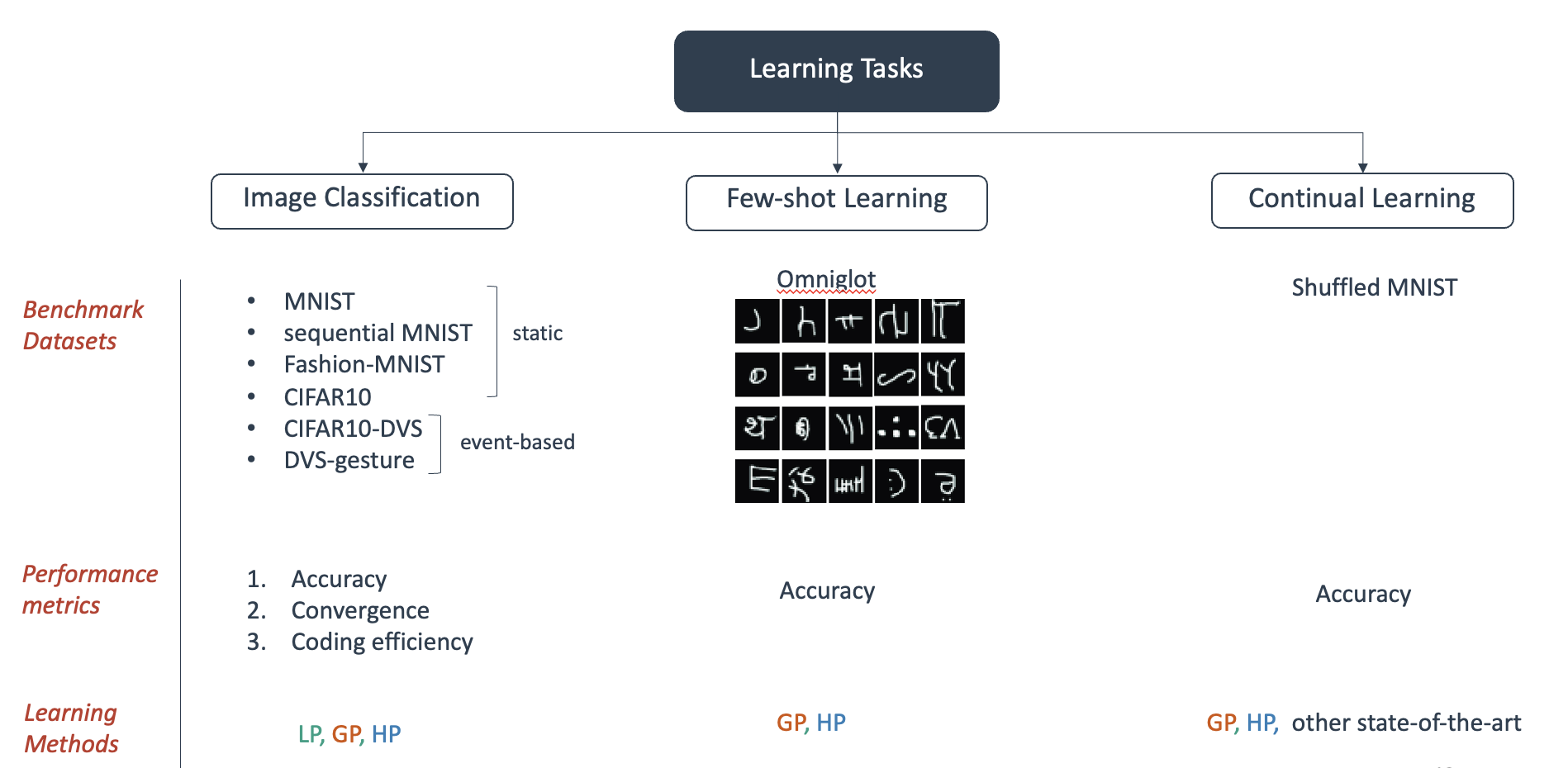
Benchmarks
The authors then validated the proposed hybrid learning on many tasks including conventional image classification tasks, few shot learning and continual learning.
Results
- On image classification tasks, the proposed method achieves high accuracies; it is inheriting the capabilities of gradient-based backpropagation in this regard.
- They show that HP achieves faster convergence than single GP method (conventional back-propagation algorithms).
They explained this result by commenting on the roles of LP and GP:
- LP acts as a small attention-network assigning high importance to the “recent past”.
- GP takes into consideration a longer time scale.
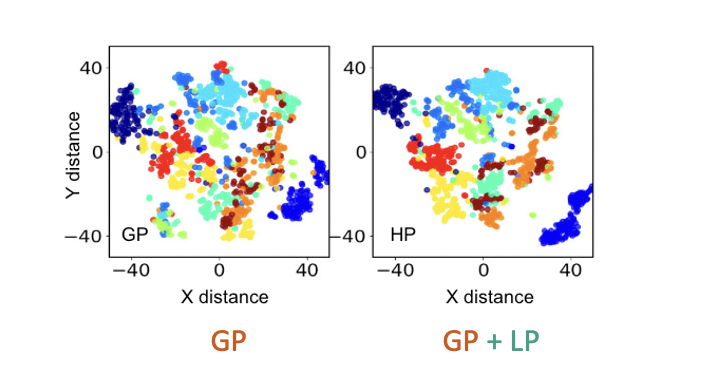
- Additionally, adding LP helps the network learn better hidden layer representation. For the MNIST dataset, this translated into better discriminability of the 10 classes. A visualization of the firing rate of the hidden layer shows that adding LP increases the distance between the classes.
- The proposed approach can support both rate and temporal rank coding (The coding scheme is about the decoding scheme used for the last layer of the network)
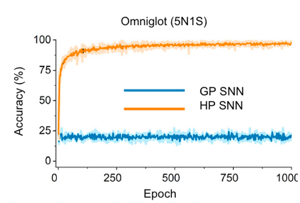
- Few-shot learning is made possible with HP while a single GP algorithm is not capable of learning feature representations from small data examples.
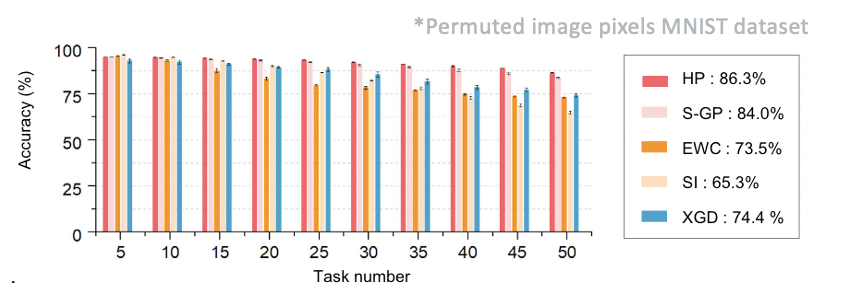
- The authors also show the results of the network on continual learning using a shuffed MNIST task and report high accuracies for up to 50 tasks. They compare their results to the state-of-the-art networks such as Elastic Weight Consolidation (EWC, 2017), context-dependent gating (XGD, 2018) and Synaptic Intelligence (SI, 2017).
My Critic
- So much work from an engineering perspective had to be put together to write this paper. The authors tested the proposed algorithm in multiple contexts, also in a simulated hardware environment.
- However, I found the paper hard to read and understand. That is mainly due to:
- Non-conventional terminologies: for example using “memory gate” to designate the reset mechanism of the neuron.
- Confusing overall methodology. It wasn’t clear why dividing the weight into two terms nor how to initialize the phasic $w(t_n)$ term (which is non-trivial).
- They highlight the importance of algorithm-hardware co-design” yet do not demonstrate it. They developed a hybrid algorithm that can fit on their chip.